L’intelligence artificielle (IA) a transformé de nombreux secteurs. En géomatique, elle permet le traitement d’images satellitaires, la modélisation 3D du territoire ou encore l’analyse de données géospatiales pour l’aménagement et la gestion des ressources environnementales et énergétiques. Ces progrès reposent sur des modèles d’apprentissage profond de plus en plus complexes et coûteux, tant sur le plan computationnel qu’environnemental.
I. Le Red AI et ses impacts
Le Red AI désigne un domaine de recherche centré sur l’amélioration des performances des modèles, notamment leur précision, au prix d’une forte consommation de ressources computationnelles. Ce courant privilégie les résultats techniques, mesurés par des indicateurs comme l’accuracy ou le f1-score, sans considérer les coûts économiques, environnementaux ou sociaux.
Un trait marquant du Red AI est l’usage de modèles toujours plus volumineux, mesurés en nombre de paramètres, ce qui accroît fortement les besoins en calcul pour l’entraînement comme pour l’inférence. BERT-large (Google) compte 350 millions de paramètres ; GPT-2 XL et Grover, 1,5 milliard ; Megatron-LM (NVIDIA), 8 milliards ; T5-11B (Google), 11 milliards. GPT-3 atteint 175 milliards de paramètres, et GPT-4 dépasse, selon les estimations, le billion.
Cette croissance s’accompagne d’une démultiplication considérable de la taille des données d’entraînement. En traitement automatique des langues, BERT-large (2018) a été entraîné sur 3 milliards de sous-mots (des unités lexicales intermédiaires, situées entre les caractères et les mots entiers, permettant de mieux gérer la variabilité du langage tout en limitant la taille du vocabulaire), contre 32 pour XLNet, 40 pour GPT-2 XL, et 160 Go de texte (≈ 40 milliards de sous-mots) pour RoBERTa, mobilisant 25 000 heures GPU. T5-11B a franchi le seuil du trillion de jetons, soit 300 fois plus que BERT.
Ces évolutions techniques s’accompagnent de coûts financiers élevés. BERT-large a mobilisé 64 TPU pendant quatre jours (≈ 7 000 $) ; Grover, 256 TPU pendant deux semaines (≈ 25 000 $) ; XLNet, 512 TPU pendant 2,5 jours (≈ 60 000 $). Certains projets franchissent des seuils bien supérieurs : AlphaGo a nécessité 1 920 CPU et 280 GPU afin de jouer une seule partie de Go, avec un coût estimé à 35 millions de dollars. L'entraînement de GPT-4 aurait lui, dépassé les 100 millions de dollars.
Le développement des modèles d’IA génère donc des coûts économiques croissants, concentrant le pouvoir entre les grandes entreprises capables de mobiliser des ressources financières, humaines et informatiques considérables. Cette escalade crée de fortes barrières pour les chercheurs indépendants ou petites structures, qui peinent à reproduire les résultats ou entraîner leurs propres modèles dans des conditions comparables.
Toutefois, si les modèles plus volumineux offrent de meilleures performances, les gains deviennent de plus en plus marginaux. La relation entre taille et performance est logarithmique : chaque progrès nécessite un accroissement exponentiel des ressources. Depuis 2012, les besoins en calcul pour l’entraînement ont doublé tous les 3,4 mois, bien plus rapidement que le rythme prévu par la loi de Moore. Malgré ces rendements décroissants, la recherche en IA continue de s’appuyer sur une intensification des ressources. Pourtant, à mesure que la recherche pousse la performance, l’impact écologique compromet la viabilité à long terme de ce modèle de développement.
L’empreinte de l’IA concerne l’électricité, l’eau pour le refroidissement, les émissions de CO₂ et la pression sur les infrastructures informatiques. Selon certaines projections, la consommation énergétique liée à l’intelligence artificielle pourrait représenter plus de 30 % de la consommation totale mondiale d’énergie d’ici 2030. Cette tendance est aggravée par les modèles de langage de grande taille (LLM) comme ChatGPT, qui nécessitent des ressources énergétiques considérables.
En effet, l’entraînement de GPT-3 a requis 1 287 MWh et généré 550 tonnes de CO₂, soit l’équivalent de 311 vols aller-retour Paris–New York. GPT-4 aurait atteint 50 GWh, l’équivalent de la consommation de San Francisco pendant trois jours. Et l’inférence, bien que plus discrète, engendre un coût énergétique massif du fait du volume de requêtes. Une seule requête à ChatGPT consomme environ 1 080 joules. Fin 2024, plus d’un milliard de requêtes étaient traitées chaque jour, soit une consommation annuelle estimée à 109 GWh, comparable à celle de 10 000 foyers américains.
Aux États-Unis, les projections soulignent l’ampleur du phénomène : en 2025, les centres de données représentent déjà 4,4 % de la consommation électrique nationale. Cette part pourrait doubler d’ici 2028, en lien avec la généralisation croissante des usages de l’intelligence artificielle. À plus long terme, les systèmes d’IA pourraient consommer jusqu’à 22 % de l’électricité résidentielle américaine
II. L’émergence du Green AI
Face à la croissance des coûts économiques et environnementaux liés à l’IA, il devient indispensable de concevoir des systèmes plus efficients. Le Green AI incarne cette approche : elle vise à développer des modèles innovants tout en minimisant leur consommation énergétique et leur impact environnemental. Cette démarche privilégie des architectures compactes, économes en ressources et à faible complexité calculatoire, afin d’atteindre un compromis optimal entre performance et efficacité énergétique. Elle met aussi l’accent sur la transparence des processus décisionnels, afin de renforcer la confiance et ajouter une dimension sociale à sa durabilité. Si l’efficacité énergétique devient un critère d’évaluation aussi important que la précision, les chercheurs pourront orienter leurs efforts vers des modèles plus responsables, bénéfiques à la fois pour l’environnement et pour l’équité sociale.
Pour traduire ces objectifs en actions concrètes, plusieurs principes et critères d’évaluation sont explorés, avec quelques exemples cités ci-dessous :

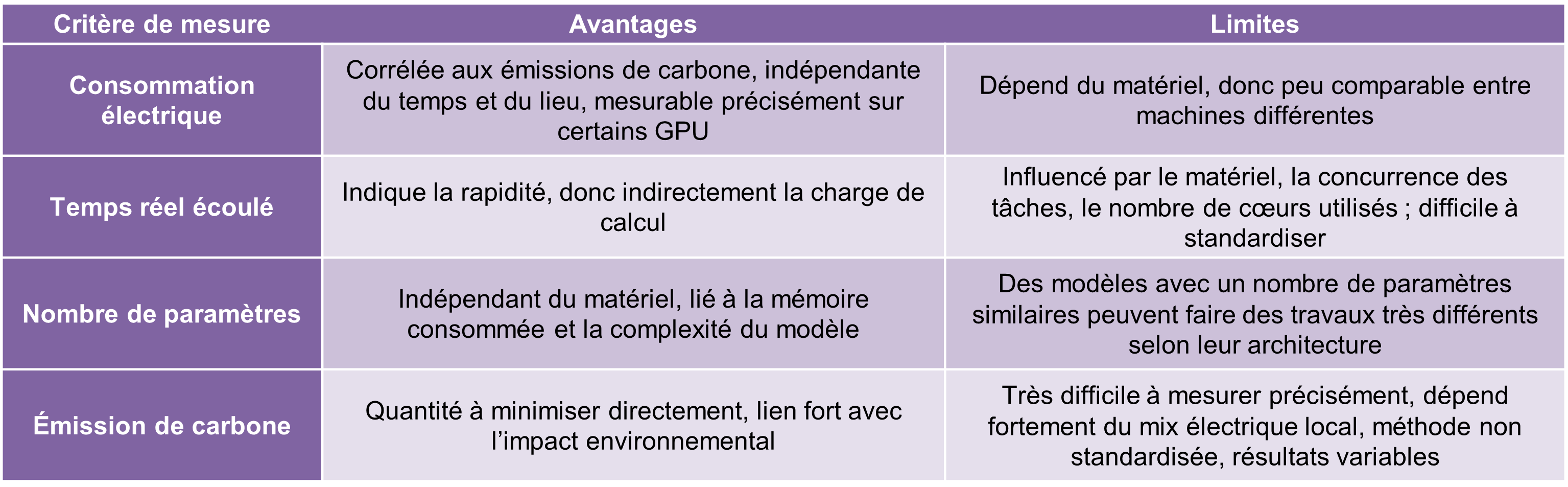
Réalisation : Clémence Boymond (2025), à partir des sources bibliographiques
Ce nouveau paradigme invite donc à un changement global, intégrant à la fois performance, transparence, accessibilité et responsabilité environnementale. Si l’on veut garantir un usage soutenable et responsable de l’IA, il est ainsi souhaitable que cette approche soit massivement adoptée et développée.
Sources :
Bolón-Canedo, V., Morán-Fernández, L., Cancela, B., & Alonso-Betanzos, A. (2024). A review of green artificial intelligence: Towards a more sustainable future.
Neurocomputing,
599(128096), 128096.
https://doi.org/10.1016/j.neucom.2024.128096
Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. In
arXiv [cs.CL].
http://arxiv.org/abs/1906.02243
Vinuesa, R., Azizpour, H., Leite, I., Balaam, M., Dignum, V., Domisch, S., Felländer, A., Langhans, S. D., Tegmark, M., & Fuso Nerini, F. (2020). The role of artificial intelligence in achieving the Sustainable Development Goals. Nature Communications, 11(1), 233. https://doi.org/10.1038/s41467-019-14108-y